Statistics homework 4
Theory: Explain a possibly unified conceptual framework to obtain all most common measures of central tendency and of dispersion using the concept of distance (or “premetric”, or similarity in general). Discuss why it is useful to discuss these concepts introducing the notion of distance. Finally, point out the difference between the mathematical definition of “distance” and the properties of the “premetrics” useful in statistics, pointing out trhe most important distances, indexes and similarity measures used in statistics, data analysis and machine learning (such as for instance; Mahalanobis distance, Euclidean distance, Minkowski distance, Manhattan distance, Hamming distance, Cosine distance, Chebishev distance, Jaccard index, Haversine distance, Sørensen-Dice index, etc.).
Practice: Prepare separately the following charts: 1) Scatterplot, 2) Histogram/Column chart [in the histogram, within each class interval, draw also a vertical colored line where lies the true mean of the observations falling in that class] and 3) Contingency table, using the graphics object and its methods (Drawstring(), MeasureString(), DrawLine(), etc). Use them to represent 2 numerical variables that you select from a CSV file. In particular, in the same picture box, you will make at least 2 separate charts: 1 dynamic rectangle will contain the contingency table, and 1 rectangle (chart) will contain the scatterplot, with the histograms/column charts and rug plots drawn respectively near the two axis (and oriented accordingly).
Practice theory: Do a personal research about the real world window to viewport transformation, and note separately the formulas and code which can be useful for your present and future applications.
Theory
In statistic, there are two classes of measurements: common tendency measures and dispersion measures.
In the first class belong all the measures that give an idea of the central values under different point of views, for instance:
- mean: the mean describes the central value in a set of values
- median: the median (or 50 quantile) is the exact value belonging to the set such that the 50% of elements are lower than that value and the other 50% of the values are greater than that value.
- mode: is the value more frequent in the distribution
In the second class belongs all the measures that describe a distance from a central value, the most common are:
- variance: described as the mean of all the distances between values and the mean powered to some constant:
-
\[\sigma^{2} = \frac{1}{n} \sum_{i=1}^{n} | x_{i} - \bar{x}|^{h}\]
- if \(h = 1\) is called mean absolute deviation
- if \(h = 2\) is called mean square deviation
-
\[\sigma^{2} = \frac{1}{n} \sum_{i=1}^{n} | x_{i} - \bar{x}|^{h}\]
- standard deviation: is the square root of the variance, used to normalize the physical dimension of values (\(m^{2}\) to \(m\))
These concepts are all dependent on each other in fact having only common tendency measurements isn’t enough, indeed exist some distributions in which values are very far to a central value that can be the mean. On the other hand, dispersion measurements couldn’t exist if tendency measurement didn’t exist.
The concept of distance is critical in statistic analysis and often is a bit different from the mathematical definition, in fact the first keeps and depends on the physical dimension of variables, mathematical distance, instead, creates an abstraction from this physical layer.
In machine learning and artificial intelligence, there exists many algorithms that use different types of distances like:
- Euclidean distance, the most common distance between two points
- Hamming distance, used to analyze the difference grade between two strings
- Melanobis distance, that measures the distance between a point and a Distribution
- Manhattan distance, that measures the distance between two points in an N dimensional vector space. Commonly used in path finding algorithms like A*.
Practice
The application allows to select every kind of CSV file and automatically selects numerical variables (integer or floating) and puts them in two combo boxes.
Once the csv is selected you can chose which couple of numerical variables analyze with scatterplot, histogram and contingency table.
Here you can find the entire project in c#.
How it works
Practice theory
In computer graphics, whenever we are dealing to real world values, and we need to show them on a computer screen it’s necessary to make a conversion from real world to viewport, in order to show those variable correctly.
As said in [1] objects inside the world or clipping window are mapped to the viewport which is the area on the screen where world coordinates are mapped to be displayed.
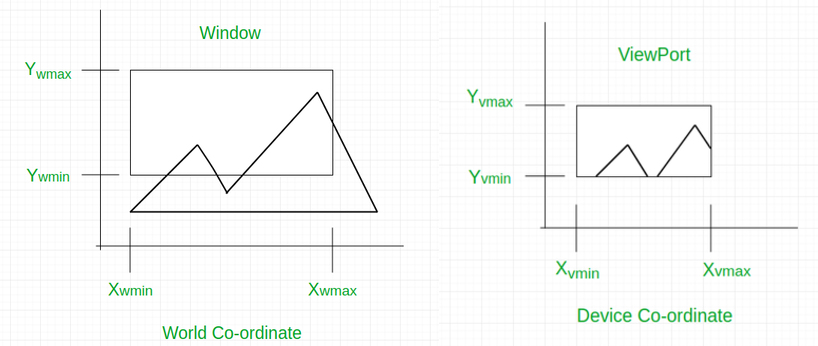
In the following sections we will see first the mathematical construction and after the code of the mapping.
Mathematical construction
Let \((x_{w}, y_{w})\) a real world point, we want to calculate the corresponding viewport’s point \((x_{v}, y_{v})\):
\[\begin{cases} x_{v} = x_{vmin} + (x_{w} - x_{wmin}) \cdot \frac{x_{vmax} - x_{vmin}}{x_{wmax} - x_{wmin}}\\ y_{v} = y_{vmin} + (y_{vmax} - y_{vmin}) - (y_{w} - y_{wmin}) \cdot \frac{y_{vmax} - y_{vmin}}{y_{wmax} - y_{wmin}} \end{cases}\]Where \(x_{vmin}\) and \(x_{vmax}\) are respectively the viewport’s start and end position on \(x\) coordinates, \(y_{vmin}\) and \(y_{vmax}\) the same as before on \(y\) coordonates. The values \(x_{wmin}\) and \(x_{wmax}\) correspond to the min and max real world value in \(x\) coordinates, \(y_{wmin}\), \(y_{wmax}\) the same as before on \(y\) coordonates.
C# Code
public (int, int) viewPortTransformValue(
Rectangle viewport,
(double, double) value,
double minX,
double maxX,
double minY,
double maxY)
{
double rangeX = maxX - minX;
double rangeY = maxY - minY;
double x = value.Item1;
double y = value.Item2;
int transformX = (int)(viewport.Left + (x - minX) * viewport.Width / rangeX);
int transformY = (int)(viewport.Top + viewport.Height - (y - minY) * viewport.Height / rangeY);
return (transformX, transformY);
}